Summary
Mosaic built an AI-enabled search assistant using deep learning and state-of-the-art language models to intelligently parse complex mechanical operation manuals and return the desired search results.

Take Our Content to Go
Introduction
With the expanding dominance of smart devices, smart search has been steadily growing. Automated search is changing how people interact with technology, especially with the increasing preference to interact with assistant devices such as Alexa. Consider a recent poll that states 68% of voice assistant users agree personal assistants make their lives easier. Given this, it is not surprising that many believe voice search will one day dominate the online search space.
Businesses that produce complex mechanical products for their customers often have to design and deliver a complex operating manual. If you have ever purchased a new washing machine or dishwasher, you can sympathize with the page thumbing through the accompanying documentation. Now, if you are a multinational manufacturing organization operating complex machinery with technical manuals that can run into the thousands – or even tens of thousands – of pages, the problem grows in scale, and the need for a more streamlined process becomes increasingly critical.
The rise of transformer-based NLP architectures and Large Language Models allows producers to build intelligent document processing solutions that scan lengthy documents and return results to users’ questions. There is a unique combination of art and science that must go into an intelligent document solution, as the architect needs to not only understand how NLP algorithms work, but which models are right for the task at hand as requirements tend to change based on the desired outputs. That doesn’t even factor in the training pipelines, MLOPs, and user acceptance required to have users trust the AI. Good thing there are organizations like Mosaic Data Science that specialize in making these solutions a reality for our customers!
In the following case study, Mosaic built a custom voice search solution using deep learning and advanced language modeling techniques to improve a manufacturing company’s customer experience with operator manual search. Mosaic developed the search technology to be unique to the customer, offering more benefits such as higher performance and more trustworthy results compared to an off-the-shelf tool.
Problem
Businesses that operate complex machinery spend significant time skimming through hundreds or thousands of pages in engineering manuals, warranty books, etc., searching for answers. A global industrial manufacturing firm noticed this pain point and wanted to deliver a better customer experience by building a digital assistant solution to help customers operate and maintain their industrial power generation equipment. The idea was to enable users to query the digital assistant through spoken commands and receive visual and verbal responses to their search.
The company turned to Mosaic Data Science for hands-on, flexible support in building the underlying document processing and natural language search software that would enable the company to make its technical manuals searchable and make the digital assistant a reality. Throughout the project, Mosaic was a true partner, offering data scientists with specific expertise in NLP techniques to match the company’s specific needs.
Development Process
Mosaic laid out a design and development plan that is still ongoing, but thanks to Mosaic’s deep learning expertise, the company has a working implementation that they are already using today. The project was broken up into three phases.
Phase 1
The first part of the project focused on extracting the content of documents and understanding the structure and relationships among the different data elements in the documents. Mosaic’s data scientists leveraged cloud OCR tools and modern NLP techniques for parsing technical documents and operation manuals. It was critical to leverage the full spectrum of image processing, text analytics, and deep learning to extract the unstructured information properly.
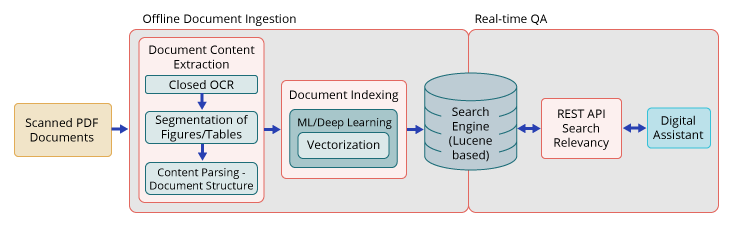
Given the customer’s needs, the standard extraction and keyword-based indexing of text elements were insufficient to meet requirements. The different data elements required additional metadata to be properly contextualized. For example, the same text could be shown in multiple sections, and the only differentiator between the two pieces of text was the section hierarchy above the text, making tracking of the section hierarchy critical. Non-textual elements, such as images and tables, needed to be matched to relevant descriptive text within these elements and in nearby document text.
Mosaic leveraged NLP techniques to develop custom algorithms tailored to our customer needs to parse text and expand the metadata associated with searchable data elements by, e.g., tracking of full section hierarchy, identification of captions, or description of images and tables in nearby text within the appropriate section.

Phase 2
Next, Mosaic indexed the extracted data elements to make them searchable. The data was indexed in a full-text search engine. As opposed to relational databases, search engines are designed to optimize the retrieval of individual search results from large numbers of potential results.
When ingesting data in a search engine there are important design decisions which affect the performance of the system. One of them is the size of the text elements (or search engines docs) being ingested. For example, input documents can be ingested as full documents, sections, paragraphs, or sentences. The former leads to search results being full documents vs specific portions or elements of the documents. The best granularity is dependent on the use case, whether the priority is to find the most relevant document or a more specific answer within a large document. For use cases of this project, Mosaic divided the text into passages, typically 3-5 sentences, and size was optimized using a gold standard set of questions and answers provided by the customer.
Traditional document search uses exact keyword matching, which ensures that words in the search query are exactly matched in the returned response. However, exact matching is unable to identify words with similar meaning or consider the contextual meaning of the search query and search results to find the most relevant answers. These limitations are overcome by using embedding-based indices. Transformer-based deep learning models can generate vector representations of individual words or sequences of words. These vectors, known as embeddings, encode meaning and context and ensure that words or phrases with similar meaning are represented by numerically similar vectors. Mosaic tuned state-of-the-art transformer models using the customer’s technical documents and created custom embedding-based indices to facilitate a more robust search and increase search results performance.
Phase 3
Next, Mosaic developed a custom search relevancy function to optimize the search results. The team leveraged the keyword and embedding-based indices and the contextual information (captions, document hierarchy, etc.) to build a custom scoring function to identify and rank results for a given query. The scoring function was validated and tuned against a gold standard set of questions and answers.
Throughout the entire effort, Mosaic recommended high-performing data architecture tools and sustainable MLOps practices to ensure a flexible and scalable solution.
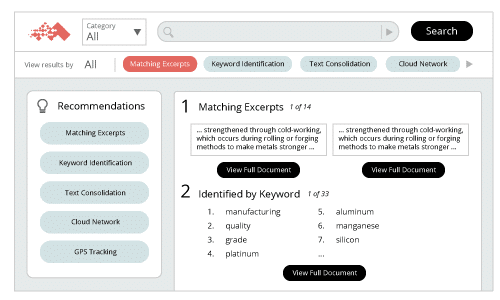
Conclusion
Today, AI-enabled search is becoming the preferred search method. A recent report revealed that 63% of individuals have utilized an AI-operated assistant using devices such as their smart phone, household appliance, laptop, and TV. Given this, many companies are exploring ways to integrate AI-enabled search capabilities into their processes and offerings. Mosaic was able to help a well-known leader in industrial manufacturing apply this concept to the creation of an AI-enabled voice search assistant solution powered by NLP and deep learning.
The ability to parse through complex technical documents and return results that users can trust is not only hugely beneficial for new sales & existing customers; but the algorithms can be tuned for any number of outputs. If internal product teams want to run a quality check on the manuals themselves, if legal needs to flag certain clauses, etc., the custom build approach allows for users to search for desired information with minimal tweaking.
The solution was built custom to the needs of the manufacturer, as exemplified by the tuning of the document parsing and indexing algorithms to unique structure and content of their documents. Mosaic was able to deliver an experience that customers currently use today when searching through manuals and other documents for important information on their purchased equipment, saving countless hours, promoting increased customer satisfaction rates and ensuring the manufacturer remains competitive in its space.


