TLDR
*The following section summarizes the contents of this blog post, you can judge how well our models perform!
The transformer architecture was pioneered by google in late 2018 to address short-comings in recurrent neural networks (RNNs) utilizing the attention mechanism.This allows the model to learn which elements are important to creating a meaningful sentence given surrounding context. Yielding a more efficient language model.
Deep learning, NLP and summaries
Natural language models have come a long way in the past couple of years. With the advent of the deep learning Transformer architecture, it became possible to generate text that could, plausibly, be passed off as written by a human. One application to this ability is to summarize long documents, distilling the conclusions and main points of the document into a succinct form, helping us humans wade through the sea of information available to us. Another application is to generate content for social media based upon summarized blogs, research, or other content. In this post, I will discuss some important concepts and technology behind document summarization.
Transformer Architecture
The Transformer architecture was pioneered by Google in late 2018 to address short-comings in Recurrent Neural Networks (RNNs). RNNs suffered from at least two flaws:
- Each memory cell of the RNN fed into the next in sequential order (see figure 1). Thus for long sequences the model would tend to “forget” things that happened earlier on.
- RNNs were not very memory efficient, so you could only load short snippets of text in memory for training.
Transformers alleviate these problems by forgoing the recurrent architecture altogether in place of an attention mechanism. The attention mechanism learns which words are more or less related to one another conditioned on all other words in the sentence. For instance in the sentence, “I ate green eggs and ham” the word “ate” would attend to “eggs” and “ham” while “green” would attend to “eggs”. In this way the attention mechanism allows the model to learn which elements are important to creating a meaningful sentence given surrounding context in a memory efficient way.
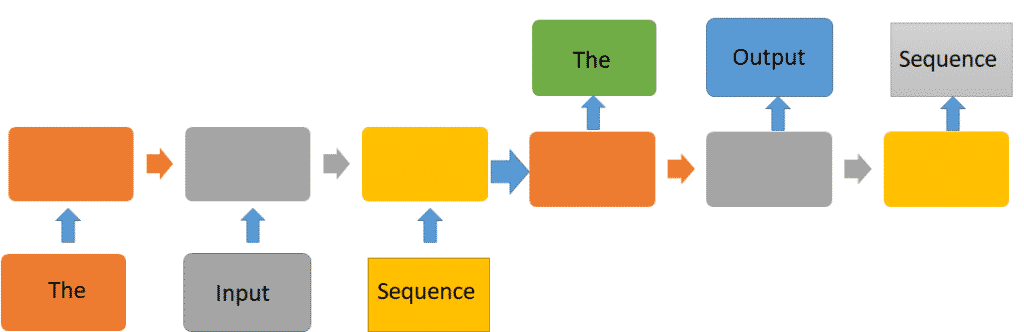
Figure 1: An example of RNN architecture for a sequence-to-sequence task. The sequence to sequence task can be to predict the next N words in a sentence or to translate one language to another. Seq-to-seq models are best for text generation. In this task the model would be trained on the output sequence as a target. The blank boxes represent the RNN block, oftentimes an LSTM.
In practice the Transformer architecture contains a stack of encoders followed by a stack of decoders. Figure 2 shows one encoder/decoder stack. Each encoder layer contains a self-attention layer followed by a feedforward layer. The purpose of the Transformer is to encode a sequence of words onto vectors weighted by all other words in the sequence. Some words (or a new sequence of words such as in a translation task) are masked in the input, and the decoder attempts to reconstruct the words that are masks. The decoder works in a similar fashion except that it also contains encoder-decoder attention layers in between the attention and feedforward layers so that the decoder can learn which words in the sequence to focus on for predicting the masked word(s) (see figure 2).
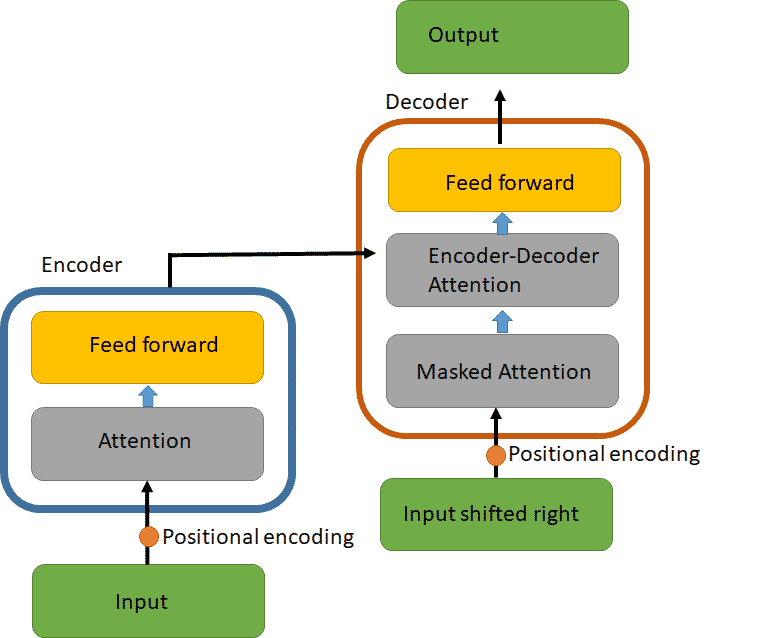
Figure 2: The Transformer model architecture. [1] Input embeddings are passed to an attention layer which are then passed to a feedforward layer. The output of the encoder is passed to the decoder, which also includes an encoder-decoder attention layer.
How is attention calculated? Attention is calculated with the use of query, key, and value vectors. To generate these three vectors you multiply the word embedding vector by the given learned matrix for that value. The query and key vectors allow you to efficiently calculate a value vector for each word that’s weighted, via the query and key vectors, by the other words in the sequence. Allowing the model to focus-in on one area of the text over another. Multi-headed attention expands this concept by calculating attention in parallel multiple times. This allows the model to attend a word to multiple sub-structures within a given sentence at once.
Abstractive vs. Extractive summaries
One of the tasks that have significantly benefited from Transformer architectures is document summarization. Generally speaking there are two types of summarization methods. Abstractive summarization takes in the content of a document and synthesizes it’s elements into a succinct summary. Extractive summarization, on the other hand, uses content verbatim from the document, rearranging a small selection of sentences that are central to the underlying document concepts. Both have their strengths and weaknesses. A weakness of the extractive approach is that the summary often doesn’t flow naturally, reading more like a series of bullet points; however each point is guaranteed to align factually with the document. On the other hand, abstractive summaries, though tending toward better flow, can sometimes make factual errors.
At Mosaic, we built several summarizers, both abstractive and extractive, for aiding researchers in literature reviews and for posting summaries on social media and blogs. Below is an example of both an abstractive summarizer in the style of a blog post and a section-by-section extractive summarizer applied to an article about mask wearing and Covid-19 spread.[1] The posts have been edited slightly for grammar, spelling, and factual accuracy.
Blog post: COVID-19 pandemic may be less likely to spread if people wear surgical face masks, according to a study published August 14,2020 in the open-access journal PLOS ONE by Tom Li from Texas A&M University, College station, and colleagues. The authors also estimated the proportion of people in the world who would wear surgical masks during the pandemic and their impact on the spread of the virus. The authors found that if masks are properly used in the population, the probability of transmission per contact will be reduced.
Extractive summarization (for literature review).
<<these are direct quotes from the article>>
Introduction:
“*During the COVID-19 pandemic that has significantly disrupted the global health system and economy, non-pharmaceutical interventions (NPIs) with potential public health benefits and little social and economic burdens should be promptly evaluated.”
*”Furthermore, effects studied in closed settings (aircraft or households) provided preliminary evidence that masks can contribute to infection prevention.
Methods:
“*We use the following equation to predict the basic reproduction number R 0 of the COVID-19 pandemic: R 0 ¼ b k D; where b is the transmission risk per contact, κ is the contact rate (numbers per time period) between an infected and susceptible individuals in the population, and D is the duration of infectivity of an infected individual measured in the same time unit used for κ.”
Results/Conclusion:
“*Based on the reported studies, we set R 0 at 2.3 to evaluate the mask impact.”
“*We report the values of M red and M cov for these seven scenarios (S1 to 7) in Table 2 .
“*It can be less than 1 when mask availability is close to 100%.”
A note on GPT-3
It would be a disservice to not mention GPT-3 in a blog post about text generation. The purpose of this post is to describe content summarization in more general terms, for a description of GPT-3 see our companion blog post here.
Conclusion
Document summarization can be a powerful tool in helping to digest large amounts of data. Contact us today to find out how Mosaic can help you with your document summarization or other language model needs.
[1]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010. [2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0237691

