Summary
Mosaic helped a North American provider of trade consulting and international freight forwarding services evaluate and improve an NLP solution that automates the tariff classification process, saving valuable resources and reducing risk while improving the customer experience.

Take Our Content to Go
Introduction
Tariff classification can be defined as the process of determining the correct tariff code for imported and exported goods. Classification of goods has an impact on customs duties, excise duties, import VAT, origin management, preferential duties, and import and export restrictions. Incorrectly classifying certain goods could lead to trouble with the government and the imposing of significant fines if the company used a tariff code with a lower duty or relied on a free trade agreement.
The Harmonized System (HS), also known as the Harmonized Commodity Description and Coding Systems, is the international standard for the classification of products. It allows participating countries to classify traded goods on a common basis for customs purposes. At the international level, the HS for classifying goods is a six-digit code system that is common across the globe. It comprises approximately 5,300 article/product descriptions that appear as headings and subheadings, arranged in 99 chapters (first two digits), and grouped in 21 sections. They are typically revised annually and updated several times throughout the year.
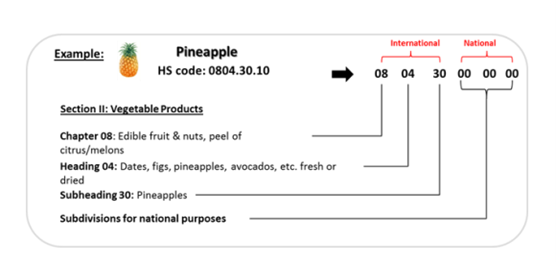
The ability to automate the tariff classification analysis and selection process harbors the possibility for significant cost savings for both the broker and the customer. With the right natural language processing (NLP) model, a brokerage could save countless hours in human review time spent sifting through headings, subheadings, chapters, and sections to find the appropriate classification, reducing the risk of human error. On the other hand, the customer can avoid overpayment by ensuring they are using the best possible classification headings, and secure quicker border clearance from customs.
Problem
A North American provider of customs brokerage services including trade consulting and international freight forwarding to importers and exporters needed data science support for an NLP solution they had developed. The company classifies product shipments based on the description of goods to the proper tariff classes. Customers can upload their entire product catalog into a web portal, and the trade company would apply the appropriate tariff. This tariff classification process can be quite arduous, taking significant time and increasing the risk of human error if done manually.
In today’s trade industry, automated services are cheap but have low accuracy rates, while manual classifications are becoming rare as they are slow and expensive. To help save resources, the trade consulting company built a classification model powered by NLP algorithms to automate the tariff assignment process for its customers. This auto-classification solution would assign HS codes leveraging best of class machine learning techniques and processes.
Upon testing the model, the company concluded there was a need for an outside partner to evaluate training data, feature engineering, algorithmic architecture, validation measures, and scoring outputs with an eye toward scalability and deployment.
Solution
Mosaic Data Science was the ideal data science partner for this effort, having developed and deployed advanced machine learning models for several customers in the transportation sector and beyond. Mosaic has a strong skillset and background in cutting-edge NLP techniques, including text classification, OCR extraction, text-based anomaly detection, text generation, contextual search engine development, and other supervised and unsupervised machine learning models.
The solution relies on NLP to break down product descriptions into machine-readable formats and performs the initial determination of word importance relative to a classification. Machine Learning (ML) algorithms and statistical models analyze, classify, and enhance those results. Next, product descriptions go through many considerations in order to get the cleanest, most descriptive, and most meaningful text. Fuzzy matching is applied to handle any misspellings, as well as synonym identification, and antonym identification. Finally, the tariff classification results are returned, and are ranked in order of an accuracy and confidence score.
Mosaic’s deep experience matching the appropriate advanced analytics tools to unique, mission-critical business decisions was a perfect match for the trade consulting company’s needs. Our data scientists were well-prepared to support and facilitate efforts to use the customer’s data to drive improved operational and strategic decisions, including reviewing algorithmic attempts to automate tariff classification, conducting an exploratory analysis, and providing recommendations on optimal modeling techniques.
NLP Algorithm Prototype Analysis
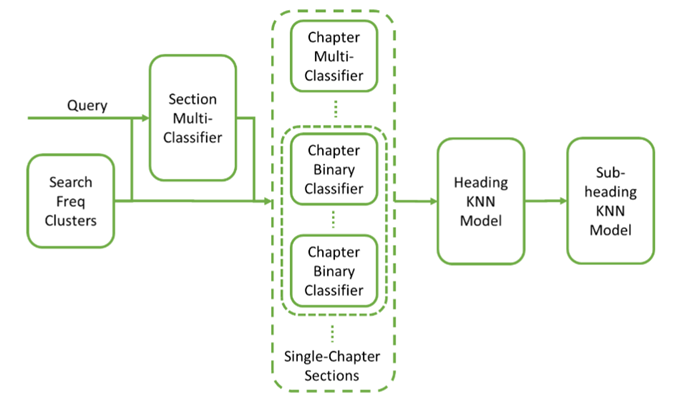
The first phase of the project involved reviewing data flowing into the model, model architectures, training, and tuning, and the resulting outputs. Mosaic’s team of data scientists worked to tune several algorithms with the aim of improving the scoring outputs and model accuracy. These included K-Nearest Neighbor (KNN) for classification search, Learning to Rank using ML, and Cluster Analysis using AI.
TensorFlow Universal Sentence Encoder (USE) Models
Using data provided by the customer, Mosaic’s skilled team of data scientists developed and tested a series of TensorFlow Universal Sentence Encoder (USE) models (pretrained transfer embedding models that classify the embeddings using dense neural networks) to provide the best recommendation for the most accurate tariff classification section. The results were as follows:
- The trained multiclass model resulted in some very accurate section recommendations, while some had confusion with other sections.
- The trained multiclass model for predicting chapter didn’t perform as well as the section-level classifier due to low representation of training data for some chapters and the similarity of certain chapter items.
- The trained individual binary (one vs all) classifier models for predicting inclusion in each section improved performance significantly over the multiclass approach for sections.
- The trained individual binary (one vs all) classifier models for predicting inclusion in a given chapter also improved performance significantly over the multiclass approach for chapters, but some chapters were still not good enough. Also, having 99 large models is cumbersome and computationally expensive.
Data Synthesis
Mosaic also created a synthesis and augmentation approach for generating additional training data for underrepresented chapters, with the benefit of increasing stability for all chapters. While this approach did not improve performance overall, it did help improve the accuracy for some chapters with few training examples.
Larger Language Models
The Hugging Face Sentence BERT model provided superior performance to the TensorFlow USE models and did not require any tuning to the query text, which had proved to be very time consuming. However, the downside was that custom words, acronyms, typos, misspellings were ignored.
Clustering
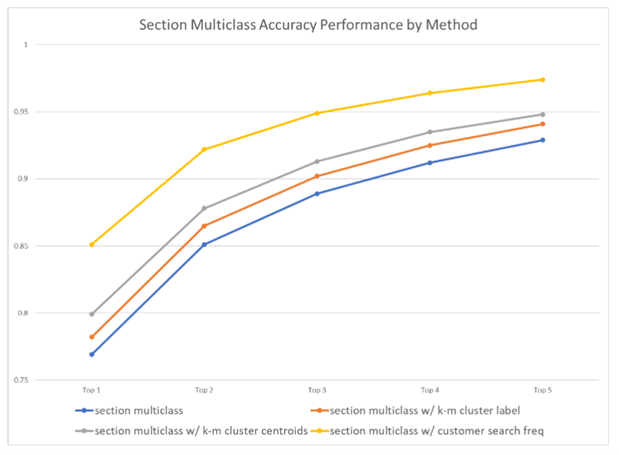
Mosaic used normalized section/chapter query history frequency as an additional feature to the clustering model (n-length vector as determined by PCA). The experiments showed a 10-20% lift for the chapter binary classifiers and an 8% overall lift for the section multiclass classifier (both based upon Sentence BERT embeddings).
Our skilled team built on these models using PCA to create actual clusters and then used the PCA-space centroid of the cluster as an additional feature for a K-means algorithm (k determined by silhouette method). This provided a nice overall lift (3%) for the section multiclass classifier, although not as much as the exact customer query history. The algorithm can be a good solution for the cold-start problem for new or infrequent customers by letting them choose their most appropriate cluster.
NLP Model Recommendations
Based on the results of the exploratory analysis, Mosaic provided a recommendation on how to design and deploy a production-grade machine learning model that would work best for the trade consulting company’s needs.
Our data scientists recommended some additional experiments be done to investigate a blend of synthetic data from the official tariff descriptions and synthetic data generated from the raw user queries. In addition, Mosaic evaluated a few additional models, including alternative embedding classifiers such as XGBoost, a powerful machine learning algorithm that requires a bit of tuning; and a Spelling Correction Model called NeuSpell, which uses a neural-net-based model to correct misspellings and typos.
Conclusion
Harmonized System (HS) code classification today is a manual and time-intensive process, yet timely border clearance is dependent on an accurate HS code classification. The sheer volume of chapters, sections, headings, and subheadings that make up the global Harmonized System for tariff classification makes the classification process an ideal candidate for automation with NLP.
The customs brokerage company classifies product shipments based on the description of goods to proper tariff classes, where customers upload their entire product catalog into a web portal, and the trade company applies the appropriate tariff. Misclassifying items can be expensive, especially if the correct tariff code has a higher duty rate than the incorrect code. This can lead to fines from U.S. Customs, additional taxes, and clearance delays at the border.
Mosaic leveraged the company’s existing customer data to design and evaluate a series of supervised learning models that successfully automated the tariff application process, delivered accurate recommendations for chapters and sections, and reduced the time and resources spent coming through classifications.
Customers benefitted from this automated process by enjoying a reduction in human-based classification errors and quicker turnaround times, and they saved money with the best possible tariff classification at the lowest duty rate.


