Summary
Advancements in compute power, computer vision, and natural language processing/generation make contextual search engine development much more feasible. Challenges remain in understanding the mechanics behind deep learning algorithms, and how to set up the data infrastructure to scale these algorithms; making this task one best suited for teams with deep data science expertise (which is why Mosaic is writing about it!)

Take Our Content to Go
Contextual Artificial Intelligence Introduction
It is no secret that artificial intelligence (AI) is powering more and more services that people use daily. With more relevance comes more scrutiny, as people wonder why they served a certain recommendation. There remains a healthy level of distrust around removing human intervention in AI system development.
One of the leading reasons for distrust is that deep learning that powers AI tends to operate as a black box with limited human context. The field of Contextual AI is gaining momentum in the marketplace as more and more people turn to deploying AI to automate & innovate decision-making processes across their organization. Contextual AI is technology that takes a human-centric approach to AI, understanding human context as interacts with humans. Contextual AI is intended to become a tool that will help set organizations apart from their competitors. Early adopters will see huge benefits in saving time and improving strategic & operational decisions.
One such Contextual AI opportunity is the ability to develop an enterprise search engine. Contextual search can be labeled as a search capability that focuses on the context of the user-generated query including the original intent of the user to show the most relevant set of results. It is quite different than traditional search technologies which focus only on keyword matching.
Keyword searches can be very powerful when the source data is well organized and structured. Search engine optimization is a great example. Marketers and web developers spend countless hours adhering to web data structures to make sure their website appears on internet searches. But most data an organization collects are not structured, and the sheer amount of time trying to label-structure that data is impossible, especially as data continues to grow. In fact, it is estimated that 80% of all corporate data are unstructured text files. Couple this with the different types of data, emails, contracts, maps, graphs, tables, etc. the problem becomes incredibly challenging to solve.
Advancements in compute power, computer vision, and natural language processing/generation make contextual search engine development much more feasible. Challenges remain in understanding the mechanics behind deep learning algorithms, and how to set up the data infrastructure to scale these algorithms; making this task one best suited for teams with deep data science expertise (which is why Mosaic is writing about it!)
Contextual Search vs Keyword Search
Consider the scenario of an airline purchasing a new engine from a manufacturer. Let’s say that an engine malfunctions due to a particular part and causes downstream delays to flights causing a ripple across the airline’s schedules, leading to angry customers. The airline mechanical team is told to scan the lengthy warranty & product information to surface potential fixes under a time crunch.
The mechanics working on this aircraft must dig through complex technical documents sacrificing valuable time. Perhaps the airline has invested in a keyword search application, and the mechanics still need to dig through a long list of results to find the necessary information. Keywords might surface all sorts of documents and data related to the engine type. The mechanical team is left with no other option than to comb through the results until they find a fix.
Contextual search can improve this process immensely. Leveraging artificially intelligent text/image mining, the mechanics’ team could enter the engine type and another modifier into their search bar. The AI then combs through the results to surface only the information related to the fix. Natural language generation & summarization can take this further by summarizing the complex documents into a few actionable results.
Not only can the mechanics fix the engine faster, but the airline gets the additional benefits of shorter delays and less operational overhead contributing to the bottom line.
Advancements in NLP Power Contextual Search
Mosaic has mused for years on the power of NLP to aid humans. For the sake of this whitepaper, we will gloss over all the steps necessary to tune deep learning algorithms to extract structured data from unstructured text, mainly the mechanics of OCR and semantic extraction, which are critical to the proper deployment of NLP in any scenario.
One of the first steps in search engine development relies on the ability of AI to ingest lengthy unstructured text and summarize this into a digestible format. Not only can AI summarize this text, but it can generate different summaries for different audiences. The recent advances in language modeling, mainly the Transformer architecture, expand on traditional NLP.
There might be a scenario where a subject matter expert needs to identify a detailed summary, finding incredibly complex and technical information. In that same scenario, an executive might need 1-2 high-level sentences from that same information. Contextual search can be tuned to stylistic preferences based on examples of similarly styled summaries and provide search results tailored to the specific user and application. If you are interested in diving into the mechanics of this process, please read our in-depth article describing our approach to solving this problem.

Threading Computer Vision to extract Image Classification
As a reader, you might be asking yourself – well, not all our data is text. Many organizations need to ingest images and return that information in a query. Take, for example, the use case of contextualizing nutritional label information. Text needs to be extracted, but deep learning also needs to identify different visual elements of where the text resides to understand how the different text elements are related to each other and their meaning.

Deep learning provides critical image processing capabilities to help automate this process. Deep neural networks can be trained to identify the regions of interest in the image, containing tables, paragraphs, images, etc. Supervised deep learning models such as convolutional neural networks (CNNs) can provide state-of-the-art performance. However, this approach requires an extensive training set – labeled example images of the information the neural network will be trained to extract – and significant compute resources such as graphical processing units (GPUs) for training and tuning the models.
Alternatively, when insufficient training data is available to train a supervised deep learning model, we can use unsupervised feature extraction methods to detect basic structural elements in the image, which can be leveraged to identify larger objects. For example, a Hough line transform can identify pixels forming a line. By identifying parallel and perpendicular lines, we can locate tables or boxes containing structured information. Other unsupervised computer vision techniques can be used to perform image segmentation, find specific shapes or remove text among others.
Combining image classification with natural language summarization and generation allows organizations to return relevant search results from any document type.
Putting this all together in the real world | Contextual Geographic Search Engine
Mosaic’s energy customer came to us with the problem of returning relevant search results on geographic sites. The firm employed several geophysicists who needed to quickly find information across millions of unstructured images and documents on geological sites dating back to the 1800s. The company does not employ these scientists to spend most of their day searching databases for relevant information, so they tapped Mosaic to build a contextual search engine.
Mosaic designed & deployed state-of-the-art language and image processing models in a scalable architecture that supports data exchange between backend model scoring and a graphical user interface (GUI). Mosaic also provided software engineers to build production data infrastructure to support the parsing of millions of documents and images.
Front End Development
The system needed to return results from text/images/tables based on keywords and custom filters. The front end allowed users to efficiently navigate over millions of documents and images by filtering on precomputed attributes, geolocating of documents on a map, and filtering with polygons drawn on a map. Mosaic’s tuned deep learning back end provided the precomputed information powering the search, e.g. image classification, image similarity, text summarization, or geolocation.
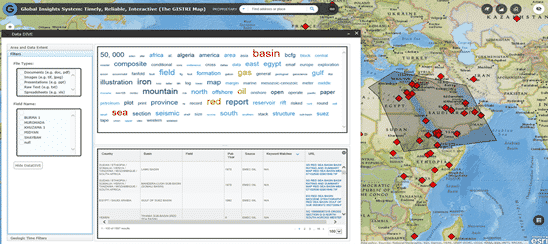
Deep Learning Features
*The full scope of this work will not be examined for the sake of brevity*
The Mosaic team deployed various techniques from NLP and Computer Vision to parse this information to extract the most meaningful results in a real-time setting. Geosentiment was derived from unstructured data by leveraging machine learning techniques and our customer internal geoscience knowledge. The obtained sentiment allowed users to extract positive/negative thoughts on specific sites worldwide. This information was key to identifying potential new leads.
Geolocating maps and documents was a crucial feature in the search process. When an image was classified as a map by a neural net, the models searched for most likely/dominant countries by extracting elements like states, cities, seas, gulfs, rivers, islands, mountains, and heuristics were assigned to identify the most likely country.
The GeoNames geographical database covers all countries and contains over eleven million placenames available free of charge. Mosaic used NLP to quickly extract millions of names from a flat data file, making sure the map returned was the desired search result. Similarly, documents were geolocated by extracting geographical and geoscience-related named entities.
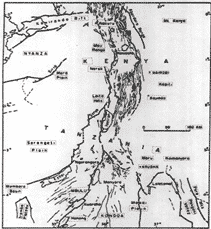
Another feature that played an important role in the search tool was image similarity. Mosaic developed a deep learning model to find images similar to the ones provided by search results. This feature allows users to browse across images and documents containing critical information which could have been missed otherwise.
Results
The contextual search engine is currently running in production, saving the energy company valuable time to return relevant information based on organizational-specific context. The tool has ingested tens of millions of documents and images, providing an unparalleled competitive advantage.
It is important to note that any analytics project is not performed in a vacuum. User feedback model/architecture enhancements are constantly made to ensure the engine continues operating at a high level.