Summary
Mosaic has been working with a leading pet Biotech company on integrating machine learning into the organization’s products, giving pet owners more visibility into the quality of life their pets have by identifying genetic traits that may impact their health or behavior. Not only did Mosaic bring innovative & creative machine-learning approaches, but we were also able to help the Biotech firm meet development deadlines in developing predictive pet disease analytics.

Take Our Content to Go
Introduction
A major vet biotechnology company needed on-demand access to a diverse and skilled team of data scientists to build upon existing data and machine learning models their team had developed. The pet startup had collected half a million genetic data points on dogs but was struggling to find the right processes and tools to get started on creating the most effective pet disease risk model and predictive model for healthy dog weight. Using this data, the company sought to leverage advanced disease risk models that exceeded the breadth and accuracy of traditional predictive pet disease analytics, which relied on sample data.
Mosaic’s Rent a Data Scientist™ program was ideal for the company to supplement its data science efforts with a true partner. Not only did Mosaic bring innovative & creative machine learning approaches, but they were also able to help the Biotech firm meet development deadlines. As a leading machine learning consulting company, Mosaic was up to the task of analyzing the startup’s existing predictive pet disease analytics models with a keen eye and recommending improvements. Mosaic built prototype predictive risk models based on the company’s genetic database to identify patterns that inform owners on certain aspects of their pet’s health, such as skin condition and weight.
Problem
For as long as people have kept pets, they have searched for ways to understand their health. Without the pet to say if they are feeling well, technological advancements in the veterinary space have continued to be driven by ways to mark a pet’s health based on behavioral, geographic, and genetic factors. Not surprisingly, machine learning offers excellent opportunities to take data from disparate sources and make accurate projections on an animal’s overall well-being.
In particular, using DNA to predict disease risk is very powerful. A polygenic risk score (abbreviated PRS) uses genomic information to assess the chances of having or developing a particular medical condition. A PRS is a statistical calculation based on the presence or absence of multiple genomic variants without considering environmental or other factors.
When examining a PRS, we can develop custom predictive pet disease analytics models to consider other external factors using data mining, machine learning, and artificial intelligence (AI) to detect correlations and patterns. Based on these trends, predictive modeling generates actionable recommendations and leads to more precise calculations of overall health, which can inform more accurate medical diagnoses and treatments — such as estimating skin disease risk levels for pets, a problem that is explored in this case study.
In addition, traditional biostatistical models like linear regression, XGBoost, and a Random Forest Classifier can vary in their effectiveness to inform on health trends that rely on medical records and DNA data. As was the case in this project, the accuracy of such models largely depends on the robustness of the dataset and the problem we aim to solve. In this case study, Mosaic built machine learning models using genetic markers and evaluated their ability to better inform dog owners on the optimal weight for their pet, an important metric that the vet biotechnology company wanted to offer customers.
As a leader in providing DNA testing for dogs and cats, the pet care company aimed to empower owners to learn about their pet’s breed mix and discover genetic factors that may impact their behavior and health. The company offers one of the top DNA tests in the market and believed it had a plethora of data that, with the proper machine learning techniques, could enhance its position in the competitive pet health space.
Predictive Pet Disease Analytics Project Scope
The vet biotechnology company collected genetic information on over 500,000 dogs and, through a partnership with a well-known pet hospital system, had the ability to obtain electronic veterinary records for many of these pets. The company’s R&D team wanted to leverage this uniquely comprehensive data set to identify genetic markers associated with specific conditions such as skin diseases and weight. Using this information, the company tasked Mosaic with building new disease risk models and healthy dog weight prediction models. Given the data set size, these models had the ability to exceed the breadth and accuracy of existing models, which relied on small, controlled samples.
The goal of the first phase of the project was to be able to extend traditional polygenic risk score (PRS) modeling, which only includes genetic risk factors, to incorporate external factors such as breed, gender, clinical history, and other features that may allow for a more accurate skin disease risk estimate for a pet. The models would determine the feasibility and potential value of incorporating PRS-like risk models into the company’s offerings.
For the project’s second phase, our customer’s R&D team wanted to predict a pet’s healthy adult weight based on identified genetic markers and other relevant features such as breed (based on an existing breed identification model), gender, and spay/neuter status. The goal was to produce a healthy adult dog weight estimate that can be communicated to customers as part of a genetic screening report.
The company had developed baseline models but wanted better performance. They required Mosaic’s expertise in designing a more reliable machine learning model that generates actionable insights and evaluating which type of model would deliver more accurate results. As this was an R&D effort, there was an appetite to explore a few different algorithms before making a production decision.
Skin Condition Predictive Risk Model
Mosaic collaborated with the vet tech company to build prototype predictive risk models for a variety of conditions, including atopic dermatitis (skin irritation without known cause), cruciate ligament ruptures (similar to ACL tears in humans), obesity, IVDD (a degenerative disc disease), and clinical anxiety. The model structure was a novel combination of traditional biostatistical techniques (GWAS & PRS) with modern machine learning.
Mosaic was also tasked with extending the risk score modeling for predicting the risk of atopic dermatitis to include geographic factors (region, local land use, etc.), evaluating risk by age, and incorporating clinical data to make the predictions more dynamic over a dog’s life.
Machine Learning Development
In developing the ML model, Mosaic tested various machine learning algorithms (Random Forest classifier, XGBoost, Logistic regression) for predicting the diagnosis. Out of which, Random Forest classifier performed the best.
Mosaic used a dataset consisting of 120,000 controls and 22,000 cases. This data was split into training and testing sets (90/10 ratio). Different evaluation metrics were then used to evaluate the model’s performance (e.g., Precision, recall, F1-Score, ROC-AUC). ROC-AUC was the main metric used all over the different models, which tells how much the model can distinguish between classes.
Mosaic proposed different ML model versions, each utilizing different features. Some versions used only the genetic panel features, and others included clinical features (e.g., gender, breed). Tracking and comparison of these models’ performance were captured using MLflow tracking.
In the ML pipeline, Mosaic also calculated the polygenic risk score (PRS) using the popular genetic analysis tool, PLINK. ROC-AUC values generated from the PRS calculation were then used as a baseline to compare the performance of the ML models.
The model was evaluated using the SHAP decision plot for better interpretability. Results showed that the ML model could better predict whether a dog will develop a condition such as atopic dermatitis, as exemplified in the image below.
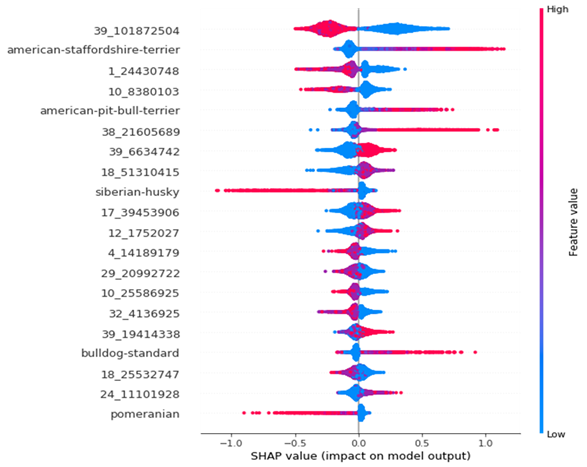
Mosaic presented these ML models into likelihood distribution and odds ratio, as shown in the chart below, as it is challenging to translate the performance metrics to owners or vets. The results differed based on the assumed prevalence of the condition in the population of dogs that will receive this information.
| Estimated Atopic Derm Prevalence | Low Likelihood (<0.75) Implied Risk | High Likelihood (>1.25) Implied Risk | Very High Likelihood (>1.5) Implied Risk | High :Low Odds Ratio |
|---|---|---|---|---|
| 5% | 1.9% | 19.5% | 24.9% | 10.2 |
| 10% | 3.9% | 33.9% | 41.2% | 8.6 |
| 15% | 6.1% | 44.9% | 52.6% | 7.3 |
Healthy Dog Weight Prediction Model
As a second part of the scope, Mosaic developed a machine learning model to produce a healthy adult dog weight estimate that could be communicated to customers as part of a genetic screening report. The ultimate objective of the model was to accurately predict a dog’s healthy adult weight based on genetic panel results, derivative information such as breed mix implied by the panel, and supporting data such as gender and spay/neuter status to help owners track their dog’s growth and increase awareness that will help owners ensure that their pet maintains a healthy weight.
The company had previously developed a preliminary machine learning model for predicting a pet’s healthy adult weight. The predictive pet disease analytics model relied on a target weight variable that came from an extensive electronic medical records (EMRs) database, including adult weights and veterinary assessment of whether the dog’s weight is healthy, overweight, or underweight.
The vet tech company tasked Mosaic with evaluating the current model, testing alternative models and new feature sets, and ultimately proposing a new model for implementation and deployment. Mosaic also advised the company on model implementation and deployment as it moved into production.
Machine Learning Development
In developing the new model, Mosaic tested three distinct machine learning algorithms to select one of these candidates to move into production. The candidates consisted of linear regression with Elastic Net Regularization, XGBoost for point prediction of the weight, and a Gradient Boosted Tree for predicting weight intervals, which performed best.
Rather than directly estimating a healthy pet’s weight, the models were trained to predict the weight ratio of a pet’s actual weight relative to a breed-based “weight factor.” The weight factor for a dog is the weighted average of reference weights for each breed detected in the dogs’ DNA. This decision proved key to maximizing predictive performance, as the models could zero in on the more subtle influence of various size-related genetic markers that were easily lost as noise against the more influential breed-related markers when predicting an absolute weight.
To properly evaluate which models performed best, an extensive evaluation was conducted using SHAP to provide model interpretability. Performance was broken down for dogs within different weight buckets to identify differences in accuracy for larger or smaller dogs. A gradient-boosted quantile regression model was also developed to be able to provide a range in which a dog’s weight can be expected to fall based on the variation in healthy weights in the training data.
Data for model selection and evaluation came from 16,100 dogs with genetic panel data and a measured weight deemed healthy at two years or older during a vet visit. Mosaic had to split the training and validation data to account for an actual ‘test’ of all models in the training dataset using stratified sampling.
The primary evaluation metric was the mean absolute percent error (MAPE), which expresses the error for a prediction as a percent of the dog’s actual weight and then averages the absolute value of these percent errors across the test samples. MAPE is effective when the error is expected to be proportional to the predicted and/or actual value. Model performance was also compared against a baseline that uses the weight factor.
The amount of machine learning testing and evaluation to produce an accurate projection of health can be challenging. Fortunately for the animal technology company, they had a partner like Mosaic, who could efficiently and effectively test algorithms with an eye towards actionability, allowing the startup to focus on their core business.
Predictive Genetic Analytics Beyond Pet Health
This case study exemplifies the power of predictive analytics for health-associated use cases when used in tandem with existing DNA-based databases and medical health records. Mosaic’s model showed that machine learning could provide more accurate risk estimates than traditional techniques alone. The machine learning model also had the flexibility to incorporate other inputs such as breed mix, clinical history, or environmental features.
Predictive analytics is a versatile technique that helps organizations unlock vital information by analyzing patterns and observing trends within specific conditions to determine the most likely outcome. Machine learning automation can be further enhanced with the Internet of Things (IoT), which can help predict the health of what is being monitored. As a leader in the full spectrum of machine learning tools & techniques, Mosaic has extensive experience applying such predictive/prescriptive analytics to solve problems for various use cases and industries.


