Summary
Mosaic helped a trucking and logistics operator optimize their machine learning deployment on Amazon Web Services (AWS). As an AWS Select Partner, Mosaic was well-positioned to deploy machine learning engineering and serverless architecture services that sped up model inference while performing a minor overhaul of the AWS architecture and code base organization.

Take Our Content to Go
Intro
In the hyper-competitive logistics world, cost savings that can be passed on to win more bids are essential. More and more logistic providers are leveraging machine learning tools to enhance performance and bring customer value. But training models is one thing, and deploying them is quite another.
A trucking logistics servicer came to Mosaic to help optimize their machine learning deployment on Amazon Web Services (AWS). The firm had developed a model to produce customer quotes for their vehicle shipping services. The quotes were very good, but the tool was deployed so that it took 2-5 minutes to return a quote and sometimes would fail to return a quote.
The client turned to Mosaic’s machine learning engineering and serverless architecture services to speed up model inference and perform a minor overhaul of the AWS architecture and code base organization in the process. Mosaic is an AWS Select Partner.
Analysis
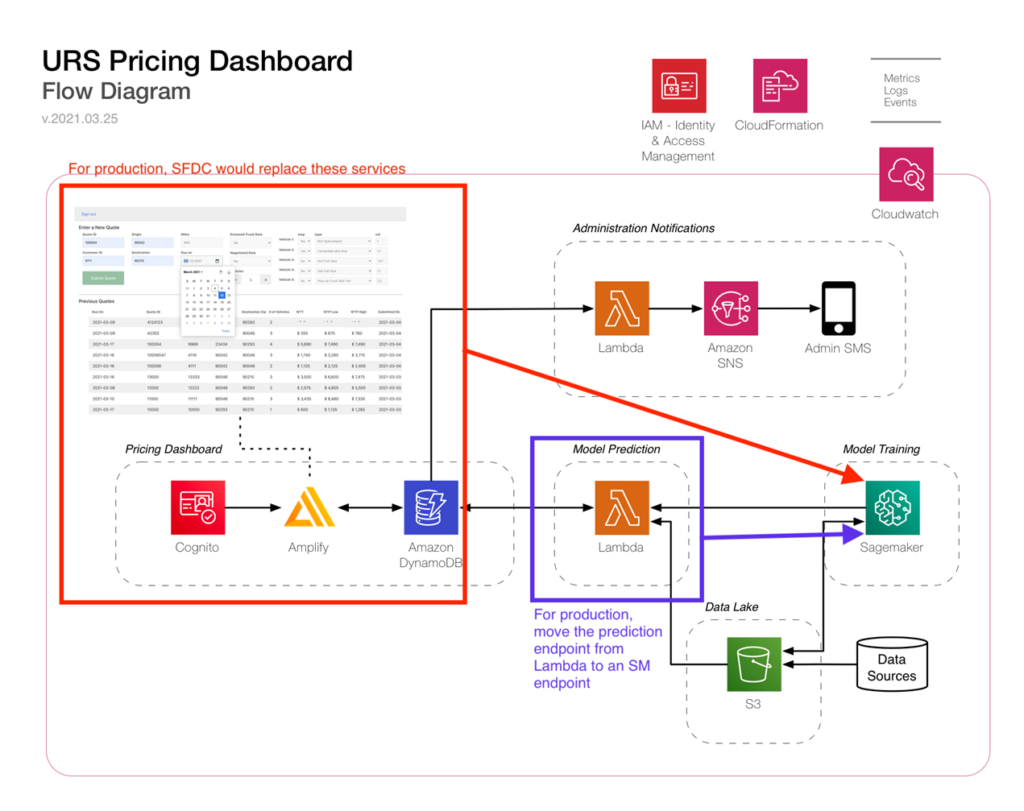
In the analysis stage of this project, the Mosaic team investigated the client’s AWS UI Console-based (manual) deployment of a serverless architecture, which featured the following components:
- Sagemaker Endpoints for model hosting (a high monthly cost)
- Lambdas for UI backend functionality (e.g., creating new quotes)
- Cognito for user authorization and login
- DynamoDB for storage and DynamoDB Streams to trigger model quotes
- Amplify for hosting a JS frontend
- S3 for hosting additional model input data
Upon inspection, Mosaic identified that the Model inference time took 2-5 minutes for execution, which was too slow to wait for the response and would sometimes fail to return, requiring users to manually refresh the frontend until the quote appeared. Overall, the manual deployment workflow was error-prone. It was difficult and time-consuming to develop, debug, and test new features in a test cloud environment that reliably mimics the production environment.
AWS ML Performance Tuning Execution
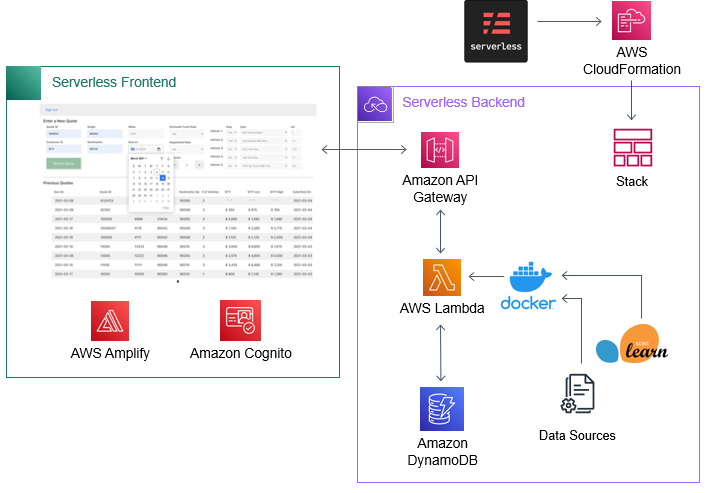
To remedy these issues, the Mosaic team refactored the codebase into a ServerlessFramework project, enabling automated and repeatable cloud deployments with a single command and a version-controlled cloud infrastructure captured in the repo. This included:
- Replacing Sagemaker Endpoints with Container Lambdas involved deploying the models directly onto Lambda’s Docker image and using provisioned concurrency to avoid the Lambda cold-start, significantly increasing speed and throughput while reducing cost.
- Moving additional model input datasets onto the Lambda Docker image increases speed and throughput.
- Implementing API keys on API Gateway to secure the Lambda model endpoints
- Refactoring the JS frontend to directly call and receive responses from the new, much faster Lambda model endpoints.
AWS ML Performance Tuning Outcome
The Model inference time was reduced to 7 seconds, resulting in a 40X increase in speed. The Model endpoint hosting saw a 10X reduction in cost. All the configurations and orchestration described above were enabled and automated using ServerlessFramework. This allowed for repeatable and automated deployments, enabling more reliable and confident development by creating cloud test environments.