Summary
Mosaic dives into the why & how of Building a Neural Search Engine in the following whitepaper. Our tool can be tuned to save countless hours of combing through documents to find relevant text, images, and tables.

Take Our Content to Go
Staying Competitive with AI
With more accessibility and ease of integration comes more adoption of AI technology. According to a recent survey conducted by IBM of global IT senior decision makers, 4 in 5 firms plan to use AI over the next five years. Properly developed and deployed AI can save organizations countless hours by validating and automating decisions. The need for experienced data science practitioners has never been greater as more and more firms indicate a desire to use AI. Trust is a priority in AI, and if you haven’t previously worked with this technology, you leave yourself open to highly-visible risks.
After OpenAI released GPT-3 in 2020, Mosaic wrote a blog series discussing this powerful technology’s potential risks and benefits. If you don’t want your AI project to wind up on the growing list of news articles about the unintended consequences of AI gone wrong, you should hire experts to help you tune these models securely to build reliable AI tools that help users make better decisions.
Background | LLM Potential is Huge but Has Limits
The transformer architecture pioneered by Google in late 2017 revolutionized the natural language processing (NLP) field. Recent advancements in the field of generative artificial intelligence (AI) have led to transformer-based large language models (LLMs) like ChatGPT, which can generate human-like conversations or solve other complex tasks, like generating code, images, or solving math problems.
One challenge with LLMs is that their answers are limited to the knowledge acquired during training. For example, a model trained using pre-Covid data will not be able to answer any questions related to the Covid pandemic out-of-the-box accurately. In addition, training LLMs are expensive due to their large size and the substantial amount of data and computing power required. Another challenge is hallucinations: LLMs will generate an answer even when the appropriate knowledge base is unavailable, leading to answers that might sound correct but are completely fabricated by the model. Online models that third parties manage also present security and privacy challenges, as any queries and data fed to those models may present a risk of disclosure or be unwittingly added to the body of knowledge that the LLM contains.
Considering these limitations. How can LLMs and other deep learning models be used to improve enterprise search without costly and time-consuming retraining and while preserving the privacy and security of organization data?
Making LLMs Agile
An approach to improving LLM performance is the retriever/reader architecture (see Figure 1), where for a given question, related context is obtained from the enterprise-specific knowledge base and fed to the deep learning model/s, which can now provide answers that consider context unseen in the training phase.
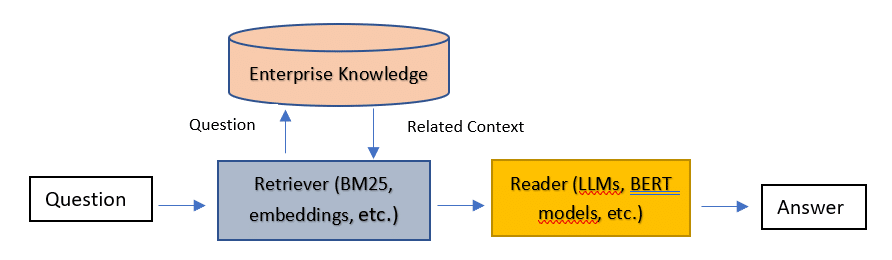
The retriever/reader architecture has three major components: the enterprise knowledge database, the retriever, and the reader.
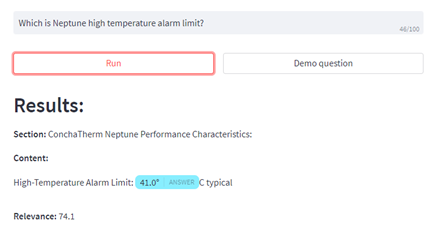
The knowledge database is enterprise-specific, containing string and/or vector representations associated with different types of information, e.g., text, images, tables, voice, etc. The retriever is the component that extracts the most relevant information from the enterprise knowledge given a specific question. A ranked list of results is obtained by matching the question to the information stored in the database. Vectorization techniques are commonly used to find the most relevant data in an efficient manner. The retriever is the second important component, and it obtains the context from which the reader later extracts specific answers. Finally, the reader is a deep learning model which finds specific answers in the response returned by the retriever. The reader can run different types of models; for example, in Figure 2, we see the answer found in our neural search engine by a question-answering model. In this example, the retriever found the relevant text in the database, which contains the answer to the input question, and the reader identified the specific numeric value answering the question.
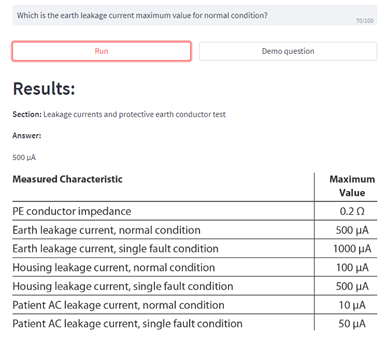
Alternatively, a table-specific model can be used to find specific cells from a table matching the user question. A BERT-based table answering model was used in the example shown in Figure 3.
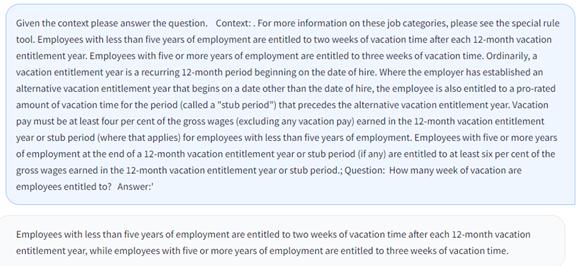
The two models above are not generative; they find information in the input text but do not create new content. When a generative model, for example, an LLM, is used as the reader component, all the text provided by the retriever is used as context to build a relevant answer given the question and the enterprise knowledge. For LLMs, this is achieved by including the retriever context and the question in the prompt. A prompt is the input text or query given to a language model. Figure 4 shows an example response provided by the open-source LLM Vicuna for the context provided by a retriever for the question, “How many weeks of vacation are employees entitled to?”.
Why Custom is Right for Reliable & Secure Artificial Intelligence
Mosaic’s Neural Search Engine combines a variety of retriever/reader solutions and query modes to meet the needs of many different use cases, including tables and text question answering, summarization, image search, or content generation powered by LLMs. Our platform supports external APIs like OpenAI’s ChatGPT or open-source models, which can be owned and executed in-house without requiring data transfer outside the organization.
For the described framework to excel, it is important that the appropriate information is available in the knowledge database. Our solution leverages state-of-the-art techniques to extract text, images or tables from documents and ingest them as searchable items in the database. Miscellaneous metadata is also ingested, which can provide additional context or filter the data as required by each use case.
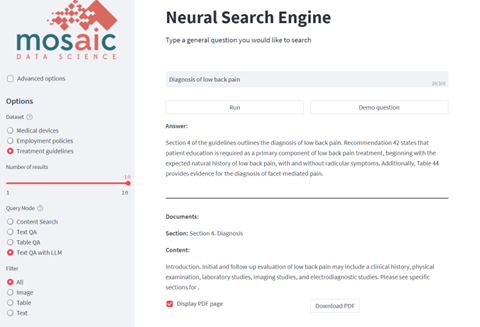
Figure 5 shows Mosaic’s Neural Search Engine in LLM mode. The front end supports the selection of multiple datasets, query modes, and filtering approaches, which can be fully customized as needed to boost search results.
Building a Neural Search Engine for Your Firm
Mosaic Neural Search Engine brings the power of state-of-the-art LLMs and other deep learning models to your organization by integrating search and generative capabilities with your enterprise knowledge stores and protecting the privacy of enterprise data. Mosaic has successfully delivered many customized search solutions over the years and continues to develop cutting-edge technologies for its customers.
The advancements made in LLMs and GenAI are not slowing down; there seem to be massive strides every week. Mosaic’s core business is everything data science, and we stay current in the evolving AI world to ensure our customers are reaping the benefits without having to sink countless hours investigating the latest developments in the field.
If you are considering leveraging an experienced partner with several successful deployments to aid in building a neural search engine, please contact us here to review if your requirements are a good fit for our solution.


