Mosaic is thrilled to announce an ongoing blog series focused on MLOps. Our data scientists will be writing about topics relevant to deploying & monitoring machine learning algorithms. Feedback is welcome in any of the comment sections!
As machine learning (ML) has matured and been pursued by more and more organizations, more ML models are being deployed than ever before. ML model deployment is very different from ML model research & development, largely because it’s easy for data scientists to ignore a host of deployment-related complexities while they focus on building the best model. Furthermore, ML model deployment is different from conventional software application deployment, largely because of ML’s dependence on training data and a “build” process that involves training the model with that data. Finally, deployed ML model monitoring involves more than typical software application monitoring because it must encompass checks for degradation in the statistical quality of model predictions often related to “drift” (changes in the underlying distribution of recent input data relative to the distribution in the training data). These differences justify the emergence of ML Operations (MLOps) as related to but distinct from DevOps and from ML model R&D. MLOps enables efficient & reliable deployment of ML models. In this post, we’ll describe the various aspects of MLOps in more detail and then discuss the MLflow Model Registry, one tool that we’ve found helpful for certain aspects of MLOps.
What is MLOps?
In a previous blog post on ensuring quality in ML model lifecycles, we defined MLOps as “the practice of leveraging software quality assurance practices, such as DevOps, in machine learning systems.” Even after work by data engineers to prepare data and by data scientists to engineer features and find an appropriate ML model type and model-training hyperparameters, there is still a substantial amount of work required to rigorously and repeatedly deploy an ML model. Deployment of ML model applications involves providing training data and a type of settings called hyperparameters to algorithm software that trains an ML model. This model-training process is not unlike a traditional software “build”. However, it depends not only the source code for training/building the model but also on training data. It produces a particular type of artifact: a trained model whose primary or sole job is to make predictions based on new data.
Like other software artifacts, trained ML models should be carefully archived along with an environment-as-code specification of the environment (e.g., supporting software packages) that they require to execute. Many issues can be more quickly resolved with robust traceability from these artifacts back to the code, settings (hyperparameters for the model-training algorithm software), and training data that were involved in creation of the artifact. Traceability back to the statistical performance achieved by the trained ML model artifact on training data is also often required for model monitoring. The trained ML model artifact needs to undergo unit testing & integration testing as part of a larger ML model application, not unlike other built software artifacts. Additionally, it must be evaluated statistically (with different data) to provide evidence that it will produce predictions on new data of sufficient statistical quality to merit deployment.
When tests are passed, the ML model application must make new predictions based on potentially messy and evolving data encountered in deployment. Care must be taken to ensure that data preparation and feature calculations are identical in training and deployment. For high-stakes ML model application use-cases, deployment should include the ability to “fail over” to a fallback approach when the input data is such that the trained ML model artifact is not able to confidently produce a prediction output. In other cases, the trained ML model artifact may be expected to provide an explanation along with each prediction, which may facilitate user trust. The trained ML model artifact & surrounding application must be monitored not only from a conventional software performance perspective but also statistically.
The statistical monitoring mechanism should involve checks for input or output drift and, if possible, an ongoing evaluation of the statistical quality of the predictions. Alerting may be required when the statistical monitoring suggests a potential issue with drift or degradation of prediction quality.
MLOps encompasses so much that it requires a wide range of skills, tools, and processes! Unless you are operating exclusively within the confines of a highly structured and uniform data, ML, and software application deployment platform, you should be highly suspicious of any single silver bullet MLOps “solution.” MLOps is really more of a set of best practices and an underlying framework justifying how to use them than a single software “solution.”
What is MLflow?
In the remainder of this post, we’ll briefly share some comments about MLflow, one tool that we’ve found helpful for certain parts of MLOps. MLflow is open-source software initially developed by DataBricks for managing the “machine learning lifecycle.” While MLflow offers other capabilities, this post will focus on the MLflow Model Registry. The MLflow model registry provides APIs (e.g., Python API, Java API) and a UI that help with the management of trained ML model artifacts. It makes the model artifacts and their environment specifications more readily available when assembling ML model applications or for other purposes such as collaborating with teammates. It helps with tracking trained model artifacts through their lifecycle, tracing back from them to the code, settings/hyperparameters, and training data used to build them, and even serving records of their statistical performance on pre-deployment training or testing data.
How we use MLflow as part of MLOps
In the screenshot below, we show the MLflow model registry UI (with model names redacted) for the MLflow instance supporting a ML model application we developed for one of our customers. This application depends on dozens (and growing!) of related ML models, and without MLflow it would be very difficult to track which version of each of these trained ML models should be deployed at any given time. While we are not yet doing so on this project, we can advance models through “stages” in the MLflow model registry as they advance through their lifecycle. This can be done through the user interface or via the MLflow API; an appropriate and coordinated process must be followed regarding stage transitions.
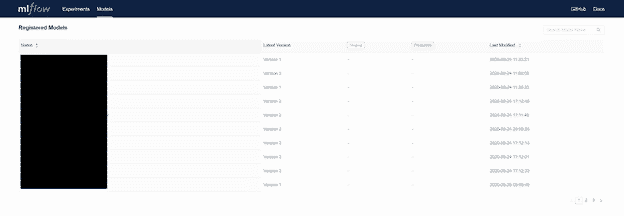
The interface and API also make it easy to review earlier versions of trained ML model artifacts.
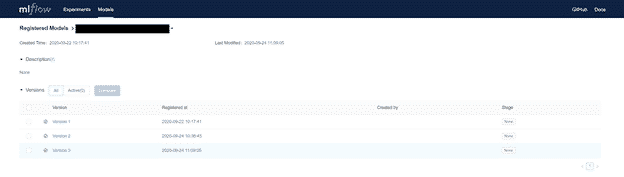
The build (MLflow “run”) that generated a particular trained ML model artifact can easily be found via the API or UI. An example (redacted) view of an MLflow “run” is shown below.
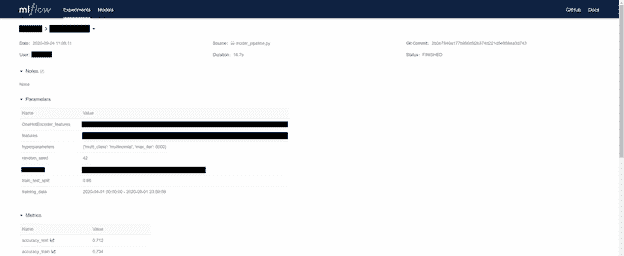
Among other things, the API and UI make readily available for each run a unique run ID, the code (Git commit hash) and settings/hyperparameters (“Parameters” pane) used in the run/build, and trained ML model performance metrics (“Metrics” pane). We use these to track and compare performance of different trained ML models.
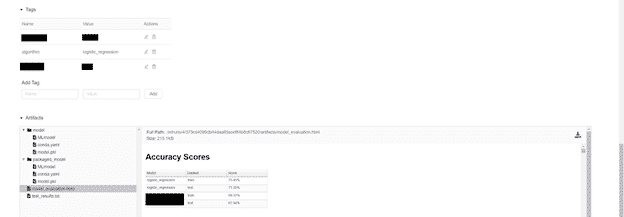
If we scroll down further on the run UI page, user-defined run “Tags” become visible, which we use for more efficient searching over trained ML model artifacts in the UI or via the API. Run artifacts can also be reviewed in the UI. The most notable run artifact is of course the trained ML model itself, which the MLflow API can return based on various types of queries. Other key artifacts include the environment specification (here a conda.yaml specifying packages in an anaconda environment) and a “packaged” version of the ML model that includes some extra pre- and post-processing logic required for deployment. Finally, artifacts also include reports on the performance of the model during the build (i.e., on the training data), in the screenshot an HTML file that one can interact with inside an MLflow UI pane.
Lessons learned about MLflow & MLOps
Overall, we have found MLflow extremely easy to use and adept at handling many issues related to trained ML model artifacts. Almost anyone who writes code appreciates the utility of git for tracking versions of software, and we often speak of MLflow as something like “git for models” when evangelizing about it internally or to customers. The API is easy to incorporate into code that trains ML models, and the UI is intuitive. The API for searching over and retrieving certain trained ML model artifacts is adequate but sometimes clumsier than expected. Setting up various types of shared backend storage like AWS S3 to serve as the MLflow “artifact store” was relatively tricky, but primarily because the MLflow documentation was not as helpful as one might hope.
Perhaps our primary complaint about MLflow is unfair because it falls outside of MLflow’s scope: MLflow does not set out to perform data versioning and it is up to you to determine how to use run/build “parameters” or other approaches to keep track of which data set was used in a particular run. Data versioning is another important aspect of MLOps that merits special attention, perhaps in a future post in this series.
Other tools & processes in support of MLOps
As mentioned earlier, there are so many skills, tools, and processes involved in MLOps. In coming posts in this series on “MLOps Tools, Tips, & Tricks”, we hope to cover MLOps topics like data versioning, other MDS-favored MLOps tools like Jenkins, Kedro, and scikit-learn Pipelines. Let us know if you have an MLOps topic you would like to hear from us about next!


