In a recently completed project with a Mosaic client, we were able to use some text mining & Natural language processing (NLP) techniques to great effects. We used a word frequency model (also called bag of words) to parse resumes and then returned a set of most likely job roles the resume was suited for. Their metrics measured our outputs to be about ten times more accurate than what they were currently using. Since these models are pretty easy to use and can also be used for different types of NLP problems.
Text Mining & NLP Basics
Natural Language Processing & text mining is a huge field that covers basically any problem that is involved with computers interacting with either human speech or written text. It is a huge field with some really cool problems and word frequency models can often be used as a starting point or a piece of the solution for many of them. They are relatively easy to set up, but as a disclaimer, they aren’t always the best solution. For example, you can use word frequency models to do sentiment analysis, but there are lots of better approaches that will give you better results. But those approaches may take a lot longer to set up. So yeah, if you want to use them, they are quick to set up and are versatile, but not always the best option out there. That’s the tradeoff. Oh, one other thing, word frequency models can get very big very fast. So that’s one other consideration to keep in mind. Before talking specifically about word frequency models, there are some terms that are good to understand.
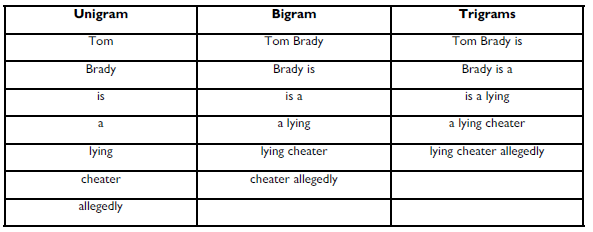
- N-grams – Refers to breaking down text into chunks of words (or sometimes letters). A unigram is a one word chunk. A bigram is a two
word chunk. A trigram is a three word chunk. And so on and so on. N-grams are a useful way to chunk up information so that you can
start to look for useful information. These are especially useful when planning on using word frequency models.
Example: Tom Brady is a lying cheater. Allegedly.
The n-grams are as follows:
- Stemming – stemming is a simple way to improve bag of words results. Stemming is usually a simple algorithm based way of ensuring that words that have the same base are tracked as the same words when we use word frequencies. This usually means that endings of words are dropped or slightly changed to ensure the same base. For example, the terms “managed,” “manages,” and “managing” are all variations of the base word “manage.” A stemmer make all of these terms be “manag” so that they share the same base. You will notice that the stemmed word isn’t an actual word, but when it comes to word frequencies, this doesn’t really matter. Why this helps will hopefully be clearer after I describe the word frequency solution.
- Lemmatization – Lemmatization is an alternate to stemming that shares the same goal as stemming. It is used to make sure that words that share the same base word all are tracked in the frequency counts as the same word. The difference between lemmatization and stemming is that lemmatization will result in a base word instead of stem. For example, using the terms “managed,” “manages,” and “managing” again, the base word would be “manage” instead of “manag”. This makes for a more readable set of features if you are interested in that. The downside is that lemmatization takes way longer than stemming does and there is no real improvement over stemming.
- Stop Words – Another way to improve word frequencies is to remove stop words. Stop words are words that don’t really have any value in a sentence because they are so common that they will not provide any differentiation in the word frequency model. Removing these words can decrease the size of your model, which can get quite big for a large training corpus.
Example: Tom Brady is a lying cheater. Allegedly.
Result: Tom Brady lying cheater. Allegedly.
Word Frequency or Bag of Words Models
In this method, the first thing that must happen is the frequencies for each n-gram must be counted. If you are doing a bigram model, then every occurrence of every unigram and bigram in the training set will be counted for each potential classification category. Each unigram and bigram count will be used as a feature in the resulting model. To clarify how this works for a unigram model for a small corpus. Let’s say we are trying to determine if someone is trustworthy or untrustworthy based on what is written about them. Below will be the corpus for untrustworthy people.
- Tom Brady is a lying cheater. Allegedly.
- Roger Goodell is incompetent and has a history of lying.
The unigram frequency counts would look like this:
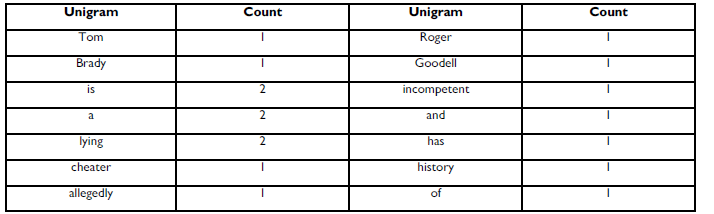
Each n-gram frequency is treated as a unique feature for the classifier. There are 14 unique unigrams in this corpus, so the trained bag of words model would have 14 features. Sentences that contain similar unigrams at similar frequencies will be more likely to be classified as untrustworthy. In the example, the terms “is”, “a”, and “lying” are the most frequent terms in the corpus. Intuitively, the terms “is” and “a” do not look like they should be indicators of anything. Additionally terms such as “and”, “has” “of” should not have any meaning. If a corpus of trustworthy examples are put together, those words are probably going to show up in that corpus as well. This is why it is ok to remove stop words when doing word frequency stuff. Those terms will show up a lot in all categories and so are meaningless in this context.
Example: Donald Sterling is a lying racist.
To classify this sentence, each unigram from the training set is used as a feature for this sentence. So we look at each unigram and count how many times it shows up in the test text. The counts for the test sentence can be seen below.
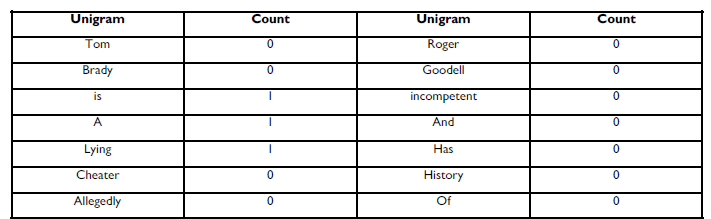
These counts are then used as the features of the test and the model uses those frequencies to determine how likely the text fits the untrustworthy classification. I want to go through one more example to show how stemming or lemmatization can improve the results.
Example: Alex Rodriguez seemingly lied when he was accused of cheating by taking PEDs.
If stemming or lemmatization was not used in the training and testing process, when the word frequency counts for this text are taken, you will get counts of 0 for the unigram “lying” and 0 for the unigram “cheater.” But the words “lied” and “cheating” are present in the test text and also share the same base words as those two unigrams, just with different conjugations. If stemming or lemmatization is used, then the unigrams “lied” and “lying” will be treated as the same unigram and “cheating” and “cheater” will be also, which will lead to a better classification of this text.
Tools
If you want to use a word frequency model, there are some libraries that can help get you up and running quickly. There is currently a MosaicATMNlpLib library that contains stop words and stemming code. Stanford NLP and Apache OpenNLP are 2 open source libraries that word frequency model tools are built in. In our text mining tests for our client, the Stanford library consistently produced better accuracy for our word frequency models. But Stanford has a GPL license where the OpenNLP library has a BSD license, so choose carefully if you are planning on using one of those libraries.
If you plan on using a word frequency model, please feel free to reach out to Mosaic. We can also talk about what you are trying to accomplish, and if a word frequency model is really your best option or if some other NLP or text mining approach would be better suited to the problem.



2 Comments
Roja Priya · September 8, 2018 at 9:20 am
Thanks for your blogs that are very helpful to learn the things.
data science course in Chennai with placement
Roja Priya · September 8, 2018 at 9:20 am
Hi, Thanks a lot for your explanation which is really nice. I have read all your posts here. It is amazing!!! You have been helping many application.
data science course in Chennai with placement