Intro
For all the data scientists venturing into computer vision and building custom vision models for different applications, we need a fast and straightforward labeling tool for creating datasets to ensure the quality of the training data so that it will not affect the performance of the Deep Learning algorithms.
There are many companies offering services to annotate the data for you or offer paid tools that have extensive automation to speed up this process. Still, the focus here is on open-source tools available today. Each tool works well for each specific purpose. The key is not to know many tools but to know which tool will work best for your project and understand how to leverage it best.
These tools vary in project management capability, automation, intuitive user experience, cloud, and private APIs, downloadable annotation file formats, and more. Some of the most common categories of labeling images in computer vision are bounding boxes, 3D cuboids, line annotation, polygonal segmentation, semantic segmentation, and landmark annotation. We will investigate some commonly used annotation tools for object detection/tracking. Mosaic has experience using several of these tools in computer vision development.
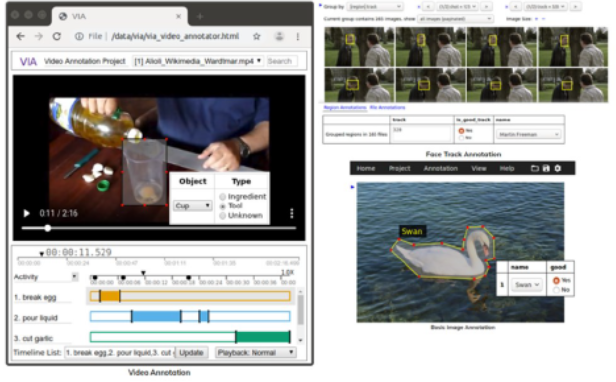
VIA is developed at the Visual Geometry Group (VGG) and released under the BSD-2 clause license, allowing it to be useful for academic projects and commercial applications. VIA is a standalone and straightforward manual annotation software for image, audio, and video. It runs in a web browser and does not require any installation or setup. The complete VIA software fits in a single self-contained HTML page of fewer than 400 Kilobytes that runs as an offline application in most modern web browsers. It supports region shapes like rectangle, circle, ellipse, polygon, point, and polyline, and the annotations can be exported in CSV and JSON file format. It also has project management functionality, which helps companies set up multiple jobs for the annotators and track the progress.
2. Visual Object Tagging Tool (VoTT)
Microsoft develops VoTT. It’s an open-source annotation and labeling tool for image and video assets suitable with cloud storage data in Azure blob. VoTT can be installed as a native application for Windows, Linux, and OSX or run from source. It is also available as a standalone Web application and can be used in any modern Web browser.
Features include the ability to label images or video frames, import data from local or cloud storage providers, and supports project tracking metrics. Once assets have been labeled, they can be exported into various formats like Azure Custom Vision Service, Microsoft Cognitive Toolkit (CNTK), TensorFlow (Pascal VOC and TFRecords), CSV, and JSON.
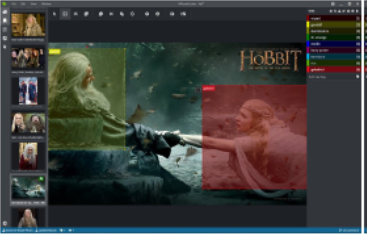
3. Computer Vision Annotation Tool (CVAT)
Intel developed CVAT web-based tool which helps to annotate videos and images. CVAT can be installed in the local network using Docker. It has project management properties where you manage users working on a project and define the user setting. CVAT has many powerful features like interpolation of bounding boxes between keyframes, automatic annotation using deep learning models, shortcuts for most critical actions, dashboard with a list of annotation tasks, and LDAP and necessary authorization etc.
Data quality for annotation can be set from very high full resolution to completely compressed. Data sources can be connected to Git repos or Git Large File Storage (LFS), a local system, or any specified URL of a server. Annotations can be exported to XML, PASCAL, YOLO, COCO, and tf.records formats. CVAT supports automatic annotation with TensorFlow Object Detection API or OpenVINO toolkit. It allows you to use custom models for auto annotation. Only models in OpenVINO™ toolkit format are supported. The Intel OPENVINO has a few Object recognition models like Resnet, inception net, Mobilnet and general face, pose, and self-driving-based models.

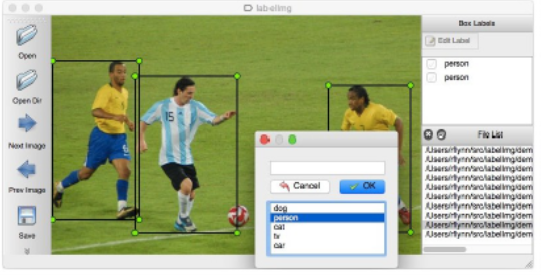
4. LabelImg
LabelImg is an open-source image labeling tool with pre-built binaries for Windows, so it is straightforward to install. It is available for Windows/Linux/Ubuntu/Mac and as a Python library in Anaconda or Docker. It only supports bounding boxes (there is also a version in the RotatedRect format and an optimized version for one-class tagging). The annotation file format is PascalVoc and YOLO. It has virtually no project management properties, but it does allow an easy way to import and visualize annotations and correct them if necessary.
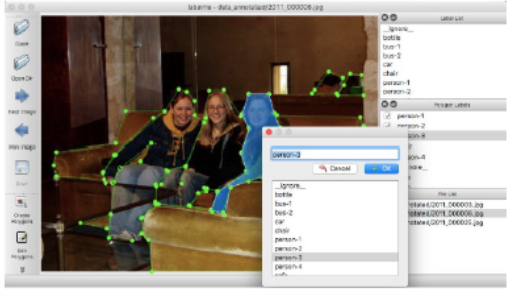
5. Labelme
Labelme is a graphical image annotation tool. It is an industry classic open-source tool by MIT for polygonal annotation. Its features are very similar to LabelImg. It is available for Windows/Linux/Ubuntu/Mac and as a Python library in Anaconda or Docker. Image annotation for polygon, rectangle, circle, line, and point are available. Image flag annotation for classification and cleaning is also functional. Annotation files can be exported in VOC and COCO-formats. It has virtually no project management properties.
Conclusion
There are more open-source tools available other than the five listed here. I have used all the above on different projects and found VIA to be the easiest for startups and smaller projects to get started. The user interface is straightforward to understand for any new annotator. The files you annotate are secured in a local folder. The project management interface is excellent, too, for more extensive projects that would need more than one annotator and tracking of project metrics.
Applications like labelme and labelImg are preferred by researchers trying to build an active learning interface for human-in-the-loop annotations as it integrates as a Python library along with other code that will be used for training and inferencing the model. For large-scale projects that use cloud storage for the data sourced, it might be convenient to use CVAT or VoTT to seamlessly transfer between the cloud storage and the tool and multiple annotators building the training data. They also allow custom models for automating the annotation, which can speed up annotation.


