Using external data to fill data modeling gaps
In the course of several recent data modeling projects, I’ve been examining data providers external to Mosaic. It’s certainly not the most exciting topic, but questions often to seem arise that are structured something like “If only we knew [X], then we could do [something awesome]” Trying to make progress on these projects has led me to chase down some data. Here are a few notes on various lessons and providers that may be useful for others in predictive data modeling.
There is a difference between a data feed and a data repository. A feed of live data can be tremendously useful for some purposes, but if no archive is being created (or elsewhere available) then this provides little for analysis work that needs to be done now. It is difficult to iterate (provide immediate value, fail fast, etc.) if you need to wait a few days, a week, or more to collect enough data to draw reliable conclusions. So, as this article continues, when I refer to a data source, I mean an archive.
Data costs money (to collect, to archive, to access, ), and there are rights and limitations associated with it. It is important to understand each of those points before trying to acquire or use external data.
For example, many in the Air Traffic Management business are accustomed to the various data sources available from the Federal Aviation Administration (FAA) and (perhaps to a lesser extent) the Department of Transportation (e.g., Transtats), including what data are provided, and the challenges associated with However, data archives are available online from most other Federal and state agencies. The interfaces to access these data vary from very confusing to almost intuitive. Sometimes these archives can be difficult to find on an agency’s website. A few that we’ve been using on recent projects include:
- S. Forest Service (www.fia.fs.fed.us/tools-data/): In case you want to know something about how much timber is harvested where and when, this is your go-to source. The interface is awkward and somewhat byzantine, but the data is eventually available.
- S. Departure of Agriculture: USDA collects a huge amount of data about planting, and harvests, both by themselves, as well as via state partners (e.g., in 2015, 2200 acres of tomatoes were planted in Virginia, yielding 31,000 tons). In addition, they collect data each day to support marketing efforts about exactly how many truckloads of each crop are being harvested by region (e.g., 4 truckload of grape tomatoes were harvested in eastern Virginia on July 12). While it seems natural that similar data sources like this would be linked, they are not. This kind of silo seems typical at many agencies, requiring significant digging to ensure that all available data from any one agency has been identified.
A number of data aggregation firms exist, providing access to a wide variety of data series aggregated from many.
A few of these are:
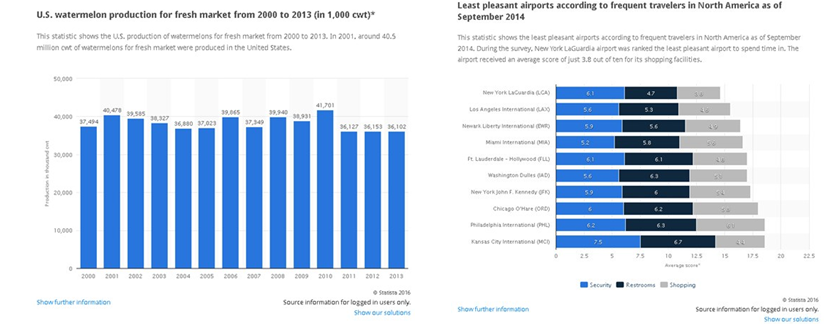
- Statista (statista.com): They claim to archive more than one million data series across a variety of industries. Some features require a paid membership. Sites like this provide a variety of data such as watermelon production as well as which airports are reportedly the least pleasant. Much of the data is scraped from government systems, but their interface is much simpler.
- Quandl (quandl.com): Like Statista, Quandl aggregates data from elsewhere, apparently focusing more on financial and economic indicators. It has proven quite useful for some data science work (i.e. for freight industry activity). They also have a slick interface on their website, far simpler than most government websites that provide the underlying data. They do have the nice feature of providing libraries for popular analysis software to wrap their API.
Another external data provider for air traffic data wold be masFlight. While we at Mosaic also archive some of what they collect, they do provide access to a lot of other data. Many of you have probably heard of them, but on a recent Volpe effort, we actually purchased some data about gate operations that proved invaluable. The data allowed us to conduct new analysis for the FAA customer, characterizing gate utilization in ways they did not previously have access to.
It is important to focus on identifying what data would actually be useful. It is very easy to begin searching for something general and end up spending far more time than necessary looking without focus. One way to aid this is to contact state and federal employees who are expert in the data – there are typically contacts list for each data archive, and we have had good success on data science projects contacting these people for information.



0 Comments